Your AI is talking.
Are you listening?
Channel reveals the invisible signals that determine whether your users convert or churn.

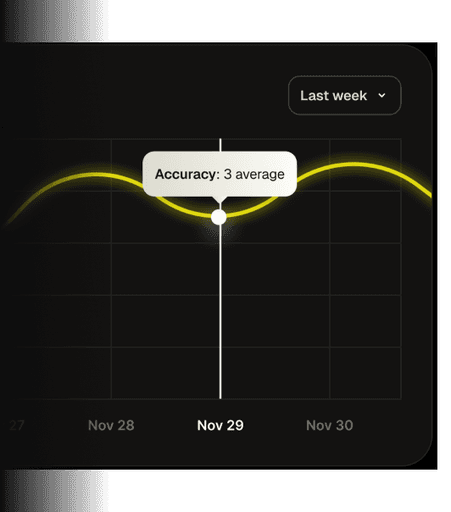

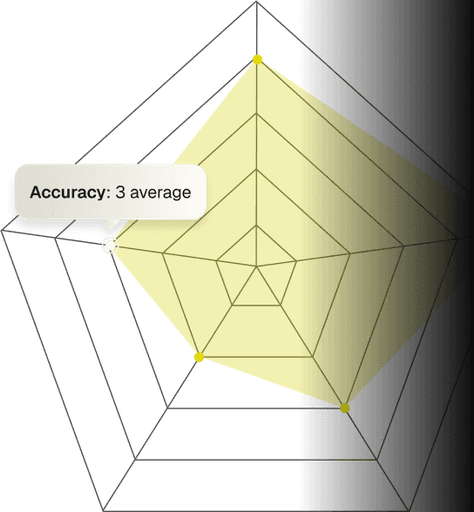

Identify underserved user segments with the highest conversion potential
Just bring your data.
Channel does the rest.
Upload your data
Get actionable insights
Channel analyzes your AI conversations and creates tailored metrics.
Monitor over time
Track changes in user behavior patterns.