JudgeMaker: RL for Optimal Judge Prompts
Jul 16, 2025
LLM-as-a-judge has emerged as the standard approach for evaluating language models at scale, but current methods face significant limitations. The two most prevalent approaches to increasing judge accuracy are fine-tuning and prompt engineering. While many fine-tuned judges demonstrate improved human alignment over prompt engineering, our early customers consistently prefer prompted judges.
This preference stems from the increased transparency that prompted judges provide. Additionally, customers preferred leveraging public model APIs rather than hosting fine-tuned models. However, base models prompted as LLM judges are often too unreliable to serve as effective evaluation metrics for AI applications.
JudgeMaker bridges this gap by combining the advantages of both approaches. Rather than fine-tuning a model to judge responses directly, we fine-tune a model to generate judge prompts that align with human preferences. This approach maintains complete transparency while achieving alignment with user preference. This entire process is accomplished entirely through synthetic data generation without requiring any user data, manual prompting, or human feedback.
Results
We evaluated JudgeMaker using the LMSYS Chatbot Arena dataset, focusing on the 215 multi-turn examples where the human interacted with two different GPT-4 variants and had a clear preference. This evaluation dataset tests hard scenarios where LLMs typically struggle to discern human preferences.
Approach | Accuracy |
|---|---|
JudgeMaker | 62.8% |
o3 (automatic prompt engineering) | 59.5% |
o4-mini (automatic prompt engineering) | 59.0% |
GPT-4o (automatic prompt engineering) | 56.7% |
The judge prompts generated by JudgeMaker achieved 62.8% accuracy, representing a 3.3% improvement over automated prompt engineering with o3.
While the evaluation for our experiment uses preference data from the Chatbot Arena, organizations can instead evaluate this approach using their internal preference data if they desire.
How JudgeMaker Works
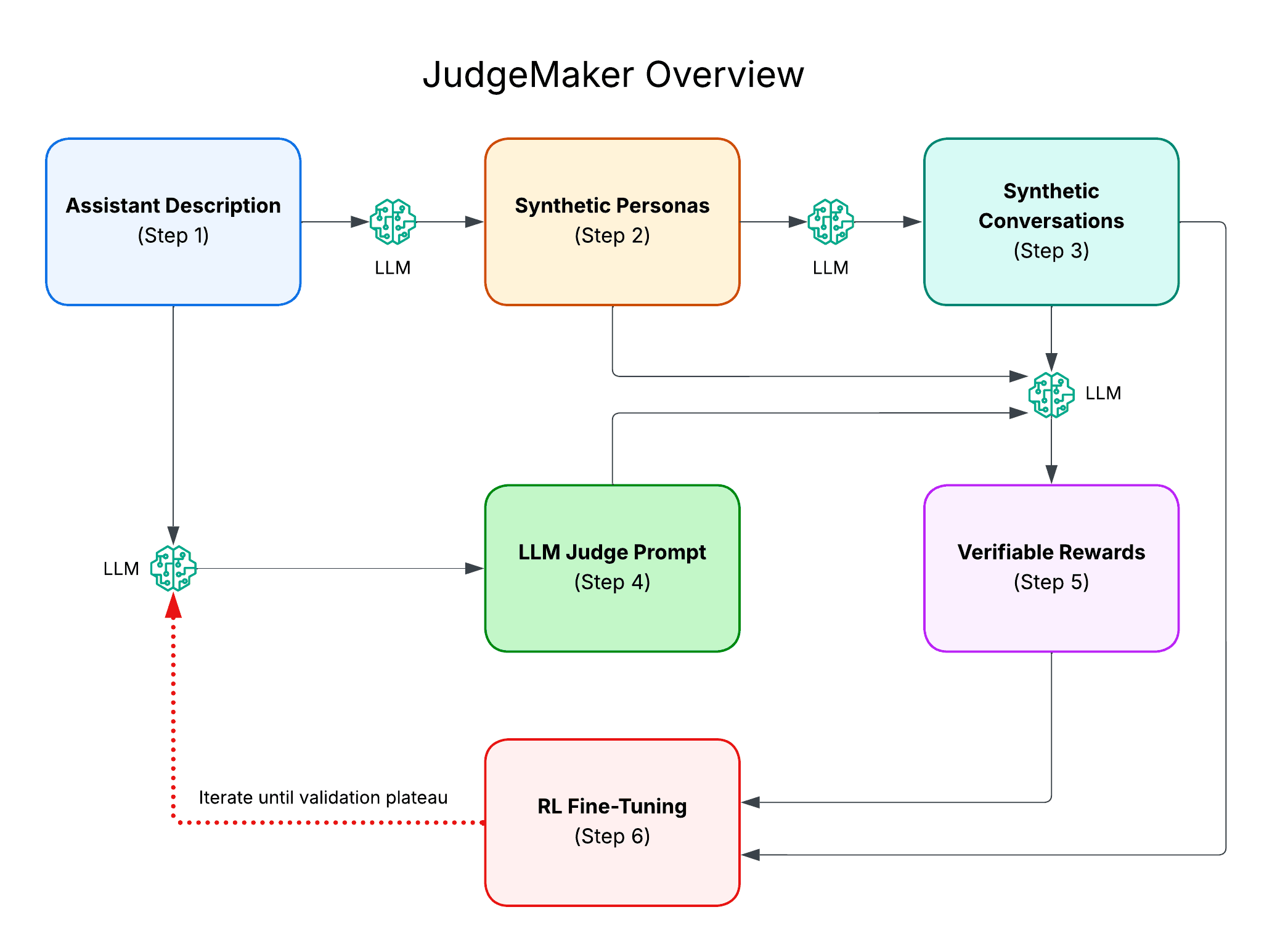
We've fully open-sourced JudgeMaker to provide transparency and allow others to build on our work. The process involves the following steps:
Assistant Description: Create a concise description of the assistant, explaining its functionality and purpose.
Synthetic Personas: Generate N diverse synthetic personas likely to interact with the assistant (we recommend using the Channel Labs synthetic-conversation-generation library).
Synthetic Conversations: For each persona, generate a simulated conversation between this persona and your assistant (we recommend using the Channel Labs synthetic-conversation-generation library).
LLM Judge Prompt: Query a reasoning model to create an LLM judge prompt that scores conversations between users and assistants on a 0-100 scale, based on the assistant description defined in step 1.
Verifiable Rewards: Assign ground truth scores for each conversation by providing the persona, conversation, and LLM judge prompt as context to an LLM query that evaluates the conversation against the judge prompt from the persona's perspective.
RL Fine-Tuning: Use an RLVR algorithm (such as GRPO) to fine-tune the policy model for a single epoch. During training, the policy model generates candidate judge prompts based on the assistant description. An LLM then generates the judge score for a conversation, given a candidate judge prompt. The reward is then calculated based on the similarity between the LLM's score and the ground truth score.
Iterative Improvement: Repeat steps 4-6 until validation loss plateaus. During each iteration, ensure that:
The LLM judge prompt generated in step 4 uses the fine-tuned model instead of the base model, improving ground-truth accuracy over time.
The starting point for the RL fine-tuning is the fine-tuned model from the previous iteration.
Why JudgeMaker Works
JudgeMaker's effectiveness stems from two key insights that enable prompt generation aligned with human preferences without requiring human feedback:
Diverse and Realistic Personas: Accurate simulation of human preferences requires both realistic and diverse conversations and personas. To ensure realism, we don't simply ask the LLM to generate conversations directly. Instead, we first generate user personas likely to interact with the assistant, then create conversations for each persona. Diversity is crucial since unless explicitly instructed otherwise, LLMs will tend to generate multiple similar personas. We address this by generating personas serially, including previous personas in the prompt, and instructing the LLM to create personas diverse from previously generated ones.
Reward Model Provided Hidden Context During RLVR: Reinforcement Learning from Verifiable Rewards (RLVR) has proven effective in verifiable domains, but LLM-as-a-judge is usually seen as a task that is not verifiable. We make judge grading verifiable by providing the reward model with hidden context not provided to the policy model, such as the user's personality and desires. This results in the judge score generated by the reward model being more accurate than the judge score generated by the policy model.
Future Work
The current JudgeMaker version fine-tunes a single model per assistant, requiring each organization to fine-tune their own prompt optimization model. However, we believe significant overlap exists between judging tasks across various assistants. We plan to fine-tune a single model capable of generating optimal prompts for any assistant, eliminating fine-tuning costs and enabling organizations to obtain optimal prompts through simple LLM API calls. Once developed, we will release this model on HuggingFace for universal access without requiring individual fine-tuning.
Implementation Details
This section provides specific details on how we achieved the results discussed in the results section.
Data Generation
For synthetic personas and conversations, we generated 32 unique personas/conversations per training epoch. We used o3 to generate personas and GPT-4o to generate both user and assistant messages in conversations. We increased the assistant's temperature to 1.1 to enhance variance in reply types and quality.
Training
We used the OpenAI reinforcement fine-tuning API with the following hyperparameters during each training iteration until convergence:
n_epochs: 1
batch_size: 4
learning_rate_multiplier: 1.0 for the first epoch, then 0.8 × (previous learning_rate_multiplier) for subsequent epochs
The reward model used a variation of o4-mini to generate the judge prompt (base o4-mini for the first epoch, then the most recent fine-tuned model for subsequent epochs). The judge prompt was then passed to o3 to generate the ground truth scores.
Evaluation
For evaluation, we used data released by the LMSYS Chatbot Arena. We focused on multi-turn conversations where both models were versions of GPT-4, but the human decided upon a clear winner. This approach allowed us to evaluate conversations that are difficult for LLMs to determine a preference, but the human had a clear preference. This yielded 215 conversations for evaluation data.
During evaluation, the judge prompt was generated using a variation of o4-mini (either base model or fine-tuned version). The judge prompt was then given to o3 to score both models' conversations, and the conversation with a higher score was predicted as having a higher human preference.
Getting Started
We've fully open-sourced JudgeMaker to provide transparency and enable others to build upon our work. Step-by-step instructions for how to run JudgeMaker usage can be found in the README. The current implementation costs approximately $200 in OpenAI API costs if you wish to fine-tune your own version for your assistant.
During our early access phase, Channel Labs is partnering with select organizations to run JudgeMaker at no cost. If you're interested in partnering with us, please contact scott@channellabs.ai.
LLM-as-a-judge has emerged as the standard approach for evaluating language models at scale, but current methods face significant limitations. The two most prevalent approaches to increasing judge accuracy are fine-tuning and prompt engineering. While many fine-tuned judges demonstrate improved human alignment over prompt engineering, our early customers consistently prefer prompted judges.
This preference stems from the increased transparency that prompted judges provide. Additionally, customers preferred leveraging public model APIs rather than hosting fine-tuned models. However, base models prompted as LLM judges are often too unreliable to serve as effective evaluation metrics for AI applications.
JudgeMaker bridges this gap by combining the advantages of both approaches. Rather than fine-tuning a model to judge responses directly, we fine-tune a model to generate judge prompts that align with human preferences. This approach maintains complete transparency while achieving alignment with user preference. This entire process is accomplished entirely through synthetic data generation without requiring any user data, manual prompting, or human feedback.
Results
We evaluated JudgeMaker using the LMSYS Chatbot Arena dataset, focusing on the 215 multi-turn examples where the human interacted with two different GPT-4 variants and had a clear preference. This evaluation dataset tests hard scenarios where LLMs typically struggle to discern human preferences.
Approach | Accuracy |
|---|---|
JudgeMaker | 62.8% |
o3 (automatic prompt engineering) | 59.5% |
o4-mini (automatic prompt engineering) | 59.0% |
GPT-4o (automatic prompt engineering) | 56.7% |
The judge prompts generated by JudgeMaker achieved 62.8% accuracy, representing a 3.3% improvement over automated prompt engineering with o3.
While the evaluation for our experiment uses preference data from the Chatbot Arena, organizations can instead evaluate this approach using their internal preference data if they desire.
How JudgeMaker Works
We've fully open-sourced JudgeMaker to provide transparency and allow others to build on our work. The process involves the following steps:
Assistant Description: Create a concise description of the assistant, explaining its functionality and purpose.
Synthetic Personas: Generate N diverse synthetic personas likely to interact with the assistant (we recommend using the Channel Labs synthetic-conversation-generation library).
Synthetic Conversations: For each persona, generate a simulated conversation between this persona and your assistant (we recommend using the Channel Labs synthetic-conversation-generation library).
LLM Judge Prompt: Query a reasoning model to create an LLM judge prompt that scores conversations between users and assistants on a 0-100 scale, based on the assistant description defined in step 1.
Verifiable Rewards: Assign ground truth scores for each conversation by providing the persona, conversation, and LLM judge prompt as context to an LLM query that evaluates the conversation against the judge prompt from the persona's perspective.
RL Fine-Tuning: Use an RLVR algorithm (such as GRPO) to fine-tune the policy model for a single epoch. During training, the policy model generates candidate judge prompts based on the assistant description. An LLM then generates the judge score for a conversation, given a candidate judge prompt. The reward is then calculated based on the similarity between the LLM's score and the ground truth score.
Iterative Improvement: Repeat steps 4-6 until validation loss plateaus. During each iteration, ensure that:
The LLM judge prompt generated in step 4 uses the fine-tuned model instead of the base model, improving ground-truth accuracy over time.
The starting point for the RL fine-tuning is the fine-tuned model from the previous iteration.
Why JudgeMaker Works
JudgeMaker's effectiveness stems from two key insights that enable prompt generation aligned with human preferences without requiring human feedback:
Diverse and Realistic Personas: Accurate simulation of human preferences requires both realistic and diverse conversations and personas. To ensure realism, we don't simply ask the LLM to generate conversations directly. Instead, we first generate user personas likely to interact with the assistant, then create conversations for each persona. Diversity is crucial since unless explicitly instructed otherwise, LLMs will tend to generate multiple similar personas. We address this by generating personas serially, including previous personas in the prompt, and instructing the LLM to create personas diverse from previously generated ones.
Reward Model Provided Hidden Context During RLVR: Reinforcement Learning from Verifiable Rewards (RLVR) has proven effective in verifiable domains, but LLM-as-a-judge is usually seen as a task that is not verifiable. We make judge grading verifiable by providing the reward model with hidden context not provided to the policy model, such as the user's personality and desires. This results in the judge score generated by the reward model being more accurate than the judge score generated by the policy model.
Future Work
The current JudgeMaker version fine-tunes a single model per assistant, requiring each organization to fine-tune their own prompt optimization model. However, we believe significant overlap exists between judging tasks across various assistants. We plan to fine-tune a single model capable of generating optimal prompts for any assistant, eliminating fine-tuning costs and enabling organizations to obtain optimal prompts through simple LLM API calls. Once developed, we will release this model on HuggingFace for universal access without requiring individual fine-tuning.
Implementation Details
This section provides specific details on how we achieved the results discussed in the results section.
Data Generation
For synthetic personas and conversations, we generated 32 unique personas/conversations per training epoch. We used o3 to generate personas and GPT-4o to generate both user and assistant messages in conversations. We increased the assistant's temperature to 1.1 to enhance variance in reply types and quality.
Training
We used the OpenAI reinforcement fine-tuning API with the following hyperparameters during each training iteration until convergence:
n_epochs: 1
batch_size: 4
learning_rate_multiplier: 1.0 for the first epoch, then 0.8 × (previous learning_rate_multiplier) for subsequent epochs
The reward model used a variation of o4-mini to generate the judge prompt (base o4-mini for the first epoch, then the most recent fine-tuned model for subsequent epochs). The judge prompt was then passed to o3 to generate the ground truth scores.
Evaluation
For evaluation, we used data released by the LMSYS Chatbot Arena. We focused on multi-turn conversations where both models were versions of GPT-4, but the human decided upon a clear winner. This approach allowed us to evaluate conversations that are difficult for LLMs to determine a preference, but the human had a clear preference. This yielded 215 conversations for evaluation data.
During evaluation, the judge prompt was generated using a variation of o4-mini (either base model or fine-tuned version). The judge prompt was then given to o3 to score both models' conversations, and the conversation with a higher score was predicted as having a higher human preference.
Getting Started
We've fully open-sourced JudgeMaker to provide transparency and enable others to build upon our work. Step-by-step instructions for how to run JudgeMaker usage can be found in the README. The current implementation costs approximately $200 in OpenAI API costs if you wish to fine-tune your own version for your assistant.
During our early access phase, Channel Labs is partnering with select organizations to run JudgeMaker at no cost. If you're interested in partnering with us, please contact scott@channellabs.ai.